TL;DR: We present NICE-SLAM, a dense RGB-D SLAM system that combines neural implicit decoders with hierarchical grid-based representations, which can be applied to large-scale scenes.
Neural implicit representations have recently shown encouraging results in various domains, including promising progress in simultaneous localization and mapping (SLAM). Nevertheless, existing methods produce over-smoothed scene reconstructions and have difficulty scaling up to large scenes. These limitations are mainly due to their simple fully-connected network architecture that does not incorporate local information in the observations. In this paper, we present NICE-SLAM, a dense SLAM system that incorporates multi-level local information by introducing a hierarchical scene representation. Optimizing this representation with pre-trained geometric priors enables detailed reconstruction on large indoor scenes. Compared to recent neural implicit SLAM systems, our approach is more scalable, efficient, and robust. Experiments on five challenging datasets demonstrate competitive results of NICE-SLAM in both mapping and tracking quality.
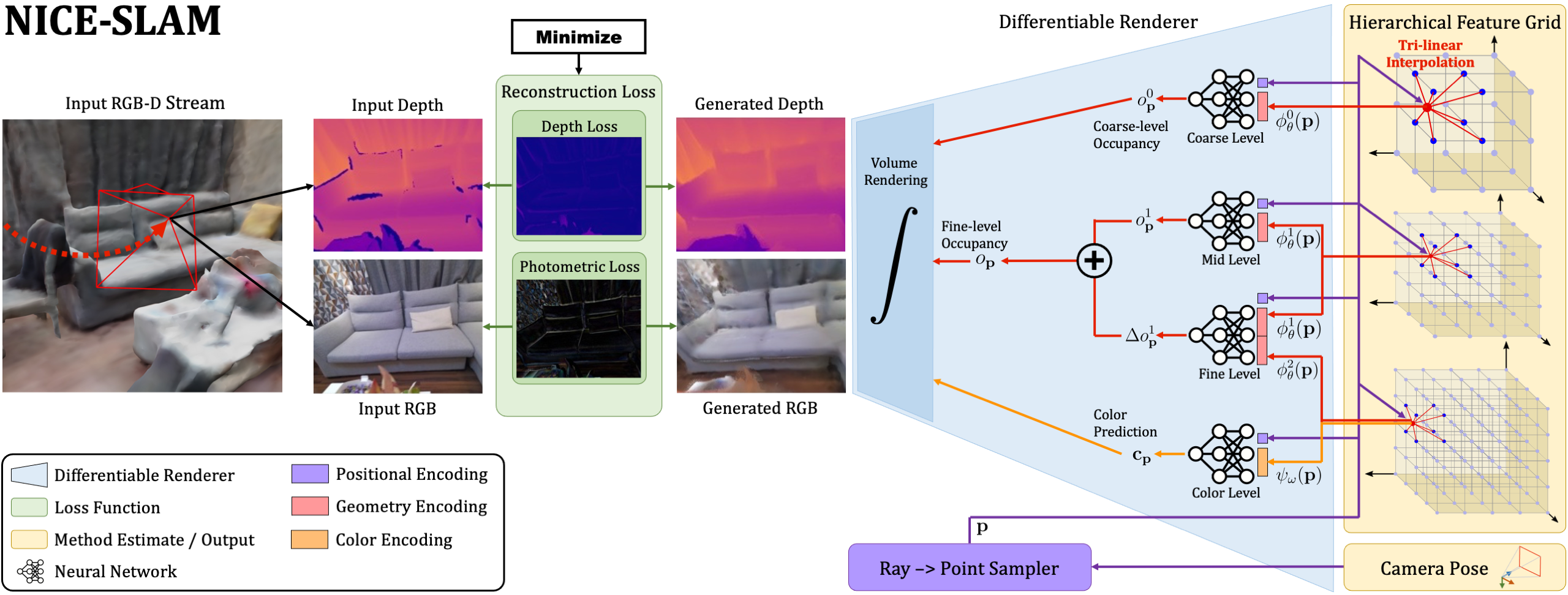
NICE-SLAM takes an RGB-D image stream as input and outputs both the camera pose as well as a learned scene representation in form of a hierarchical feature grid. From right-to-left, our pipeline can be interpreted as a generative model which renders depth and color images from a given scene representation and camera pose. At test time we estimate both the scene representation and camera pose by solving the inverse problem via backpropagating the image and depth reconstruction loss through a differentiable renderer (left-to-right). Both entities are estimated within an alternating optimization: Mapping: The backpropagation only updates the hierarchical scene representation; Tracking: The backpropagation only updates the camera pose. For better readability we joined the fine-scale grid for geometry encoding with the equally-sized color grid and show them as one grid with two attributes (red and orange).
As can be observed, our NICE-SLAM produces sharper and cleaner geometry. Also, unlike the global update as shown in iMAP, our system can update locally thanks to the grid-based hierarchical representation.
To further evaluate the scalability of our method we capture a sequence in a large apartment with multiple rooms.
NICE-SLAM is able to handle dynamic objects. Note that the airship and toy car is not wrongly reconstructed.
Here, we simulate large frame lost. The video show current tracking camera pose as well as rendered images for each tracking iteration. The ground truth camera is shown in black, the current tracking camera is shown in red.
We can notice that NICE-SLAM is able to fast recover the camera pose thanks to the prediction from the coarse-level (shown in cyan).
@inproceedings{Zhu2022CVPR,
author = {Zhu, Zihan and Peng, Songyou and Larsson, Viktor and Xu, Weiwei and Bao, Hujun and Cui, Zhaopeng and Oswald, Martin R. and Pollefeys, Marc},
title = {NICE-SLAM: Neural Implicit Scalable Encoding for SLAM},
booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
month = {June},
year = {2022}
} NICE-SLAM
NICE-SLAM