TL;DR: We present OpenScene, a zero-shot approach to perform novel 3D scene understanding tasks with open-vocabulary queries.
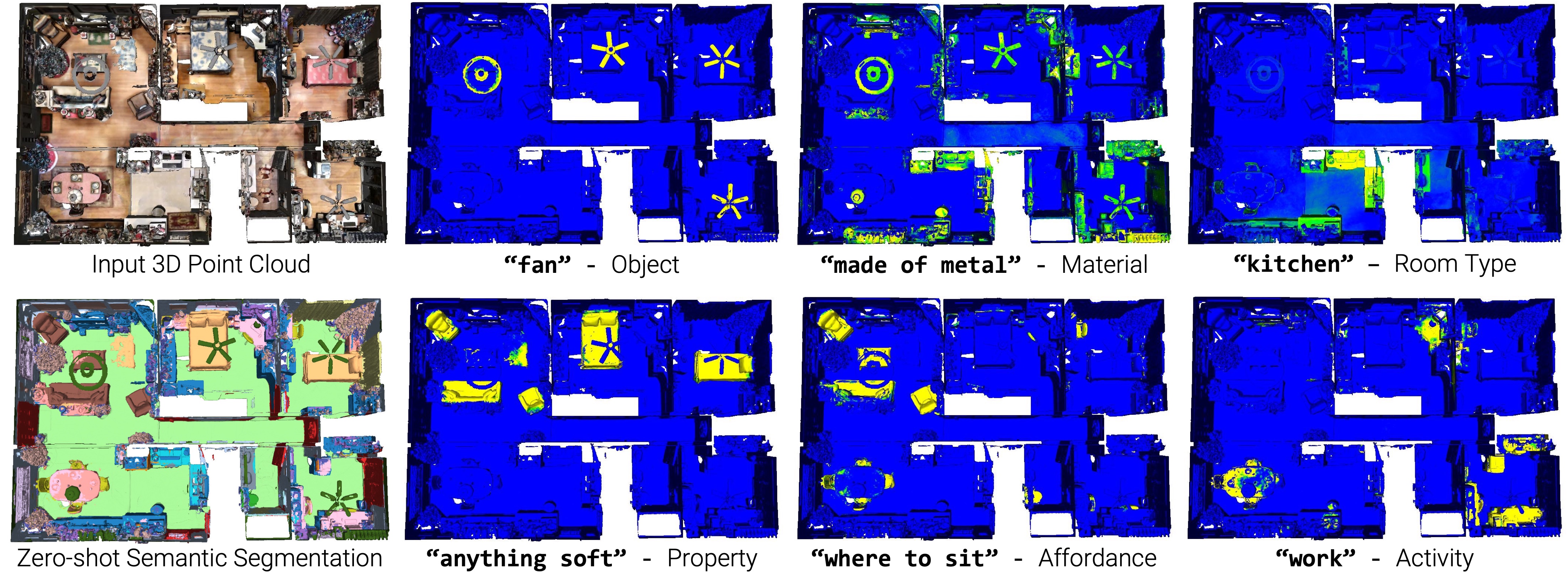
Traditional 3D scene understanding approaches rely on labeled 3D datasets to train a model for a single task with supervision. We propose OpenScene, an alternative approach where a model predicts dense features for 3D scene points that are co-embedded with text and image pixels in CLIP feature space. This zero-shot approach enables taskagnostic training and open-vocabulary queries. For example, to perform SOTA zero-shot 3D semantic segmentation it first infers CLIP features for every 3D point and later classifies them based on similarities to embeddings of arbitrary class labels. More interestingly, it enables a suite of open-vocabulary scene understanding applications that have never been done before. For example, it allows a user to enter an arbitrary text query and then see a heat map indicating which parts of a scene match. Our approach is effective at identifying objects, materials, affordances, activities, and room types in complex 3D scenes, all using a single model trained without any labeled 3D data.
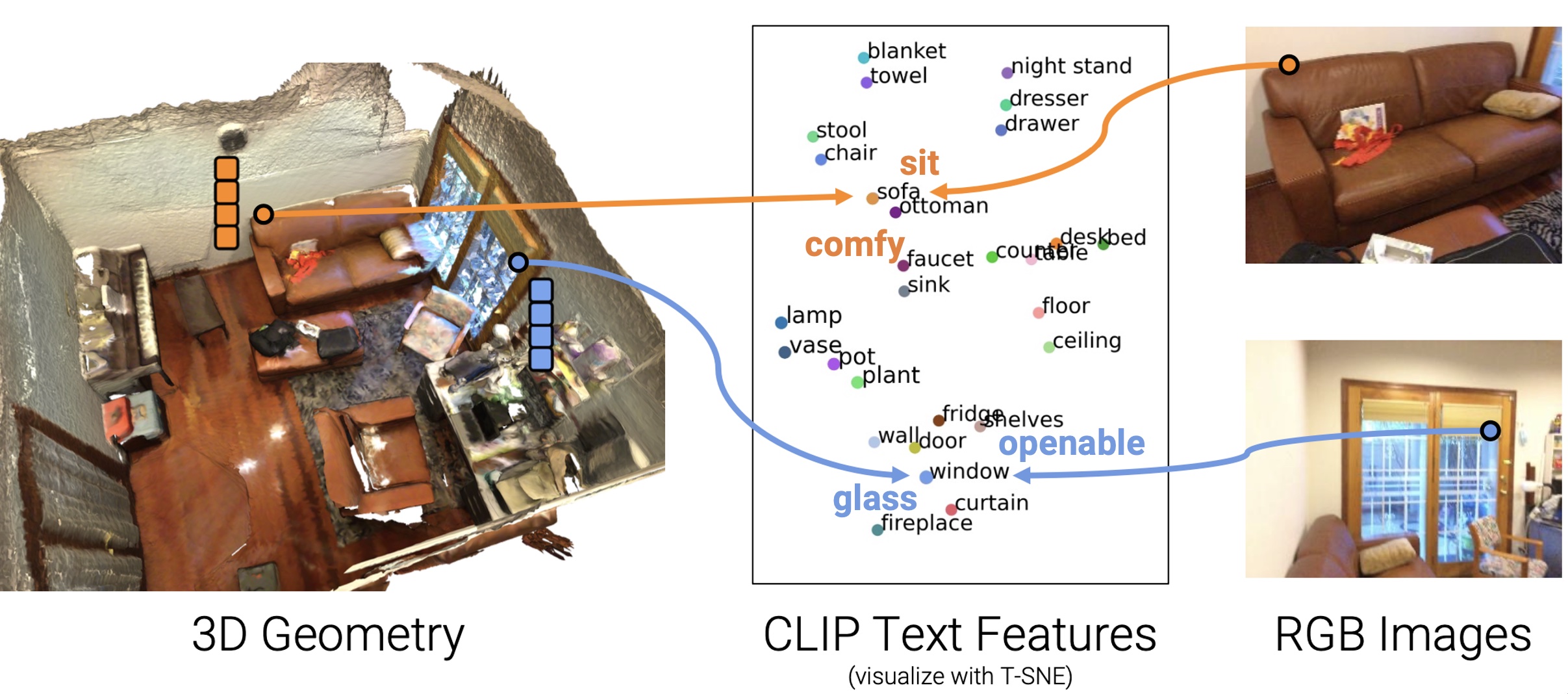
Our key idea to address this broad set of applications is to compute a task-agnostic feature vector for every 3D point that is co-embedded with text and images pixels in the CLIP feature space. After, we can use the structure of the CLIP feature space to reason about properties of 3D points in the scene, e.g. sit, comfy, glass, openable, etc.
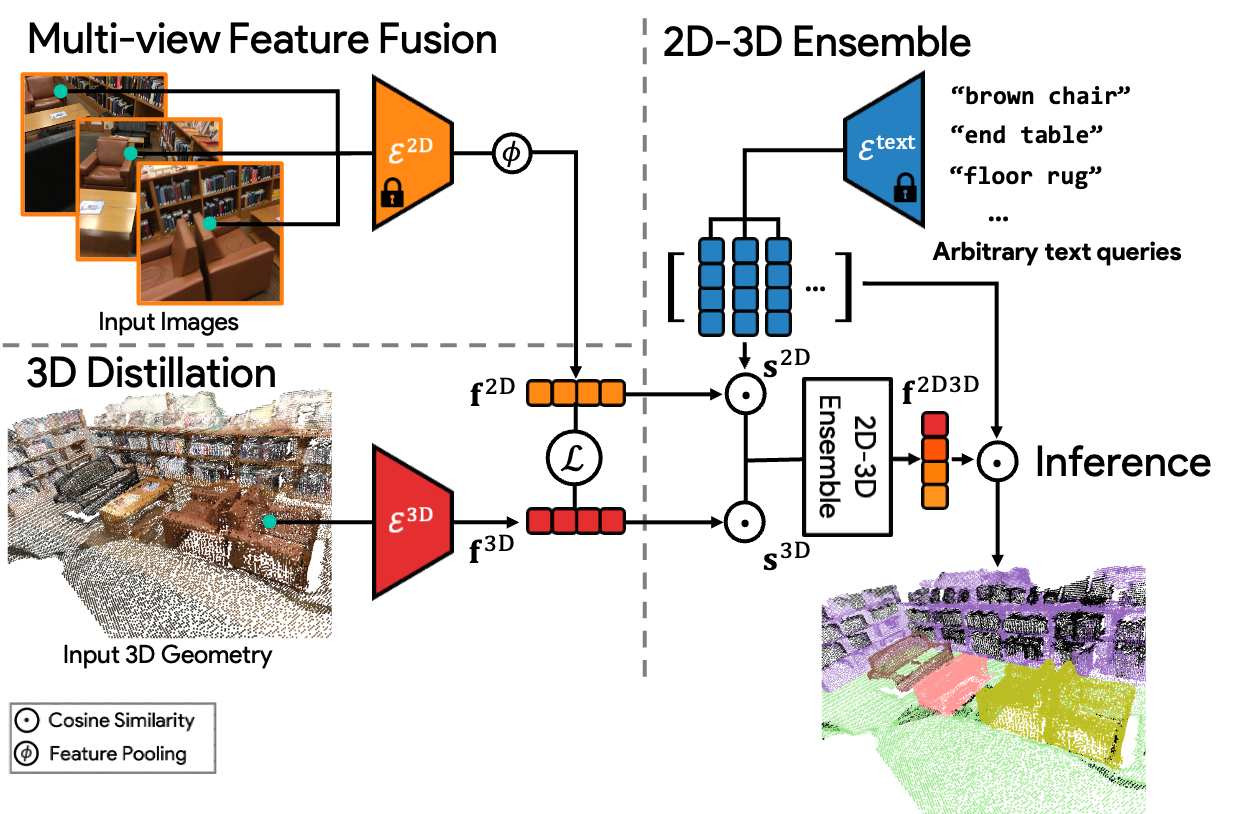
How to produce text-image-3D co-embeddings?
1. Multi-view feature fusion. Given a point in a 3D scene and its corresponding posed images, we first use the CLIP-based image semantic segmentation model (LSeg/OpenSeg) to extract per-pixel features for every image, and then use multi-view fusion with weighted averaging to project the fused feature to 3D points.
2. 3D Distillation. To take full advantage of the 3D nature of the data, we also distill a 3D Sparse UNet, with a cosine similarity loss to predict the 2D fused features from only 3D point positions.
3. 2D-3D Ensemble. we ensemble the 2D fused and 3D distilled features to a single feature vector for every point based on similarity scores to a labelset.
@inproceedings{Peng2023OpenScene,
title = {OpenScene: 3D Scene Understanding with Open Vocabularies},
author = {Peng, Songyou and Genova, Kyle and Jiang, Chiyu "Max" and Tagliasacchi, Andrea and Pollefeys, Marc and Funkhouser, Thomas},
booktitle = CVPR,
year = {2023}
}